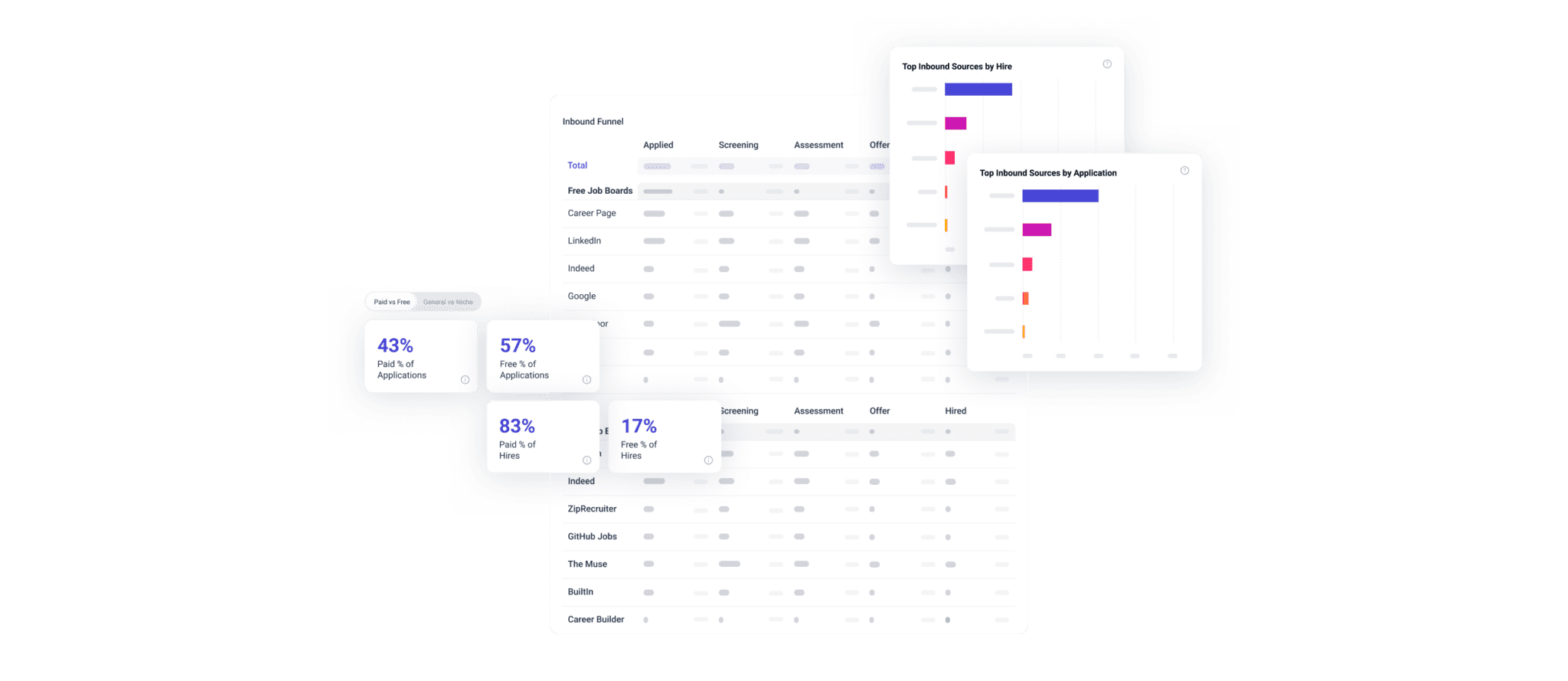
Clear recruiting analytics offer a full picture of each of your jobs and the trends in your talent pipeline overall. But you can’t get clear recruiting analytics without clean data.
Essentially, you get out what you put in when it comes to analytics. So it’s vital to get recruiting analytics basics right by collecting full pipeline data on each job, ditch evergreen jobs, and tie candidates to jobs. You also need to train your team on proper data management and incentivize clean data to get clear, actionable recruiting analytics.
Full pipeline data is metrics on every stage of a job’s hiring process. Not just ‘this many women applied,’ but ‘this many women applied, this many received interviews, this many received an offer.’ Full pipeline data enables you to diagnose issues at every stage of the hiring process.
Hiring for any one job is important, but successfully hiring for all jobs at the company is far more important.
Clear recruiting analytics can show you trends that are impacting your entire hiring process. They can highlight what you’re doing well and what you’re doing poorly, giving you a roadmap for improving your recruiting efforts.
To do that, though, you need full pipeline data for each and every one of your jobs. This is critical. If you want actionable analytics that have real impact, you need full pipeline data on every job.
2. Ditch the ‘evergreen’ jobs

Many companies that hire certain positions over and over will just keep a job open. Or they’ll edit the job but not save it as a new job, so they have no idea at what point the post attracted the highest-quality candidates. These evergreen jobs are problematic for a variety of reasons.
Evergreen jobs are recruiting analytics killers because they don’t reveal what’s working and what’s not working at every stage of your most common recruiting efforts. They don’t close and can’t provide full pipeline data.
It’s impossible to know how many applicants go through each stage of every round of hiring. Meanwhile, you can’t tell whether a specific round resulted in a hire. And, crucially, it’s impossible for you to gauge your cost-per-hire.
Evergreen jobs also have a visibility issue. Candidates don’t want to see jobs that are old and presumably closed come up in their job board searches. A good search experience requires job boards to suppress older jobs. In other words, evergreen jobs become invisible.
Evergreen jobs can also turn candidates off of other positions in your company. A candidate may apply to an evergreen role at a time when you’re not hiring and never receive a response. Receiving no response or timeline for the hiring process makes candidates feel like your company isn’t interested in them. They’ll focus their efforts elsewhere on companies that are.
3. Tie every candidate to a job
Clear recruiting analytics provide a full pipeline picture of each of your jobs, but only if you tie candidates to specific jobs and move them through the system in real time.
It’s hard to get a picture of how candidates move through the hiring stages without an accurate record of it in the system. And it’s impossible to get a complete picture of any job if candidate information is missing from a job’s dataset altogether.
If you like to retarget candidates, you can’t do that without updating their status as rejected in the system. If you don’t retarget, there’s no point in tagging candidates, but collecting them in an applicant tracking system (e.g., Workday, SmartRecruiters) isn’t the answer. It muddies your analytics.
4. Incentivize clean data for clear recruiting analytics
Incentive structures for recruiters often focus on how many candidates they convert from one stage of the hiring process to the next. It’s perfectly logical, but it also prioritizes short-term gains over long-term gains.
In that structure, a candidate accepting an in-person interview after a phone interview is a win while a candidate declining is a loss. To avoid having that loss count against them, recruiters may wait until a candidate accepts an interview to advance them to the interview stage in the ATS.
But dropouts are important for data science too. High dropout rates and late-stage dropouts can signal an overly long hiring process or other problems that are turning candidates away. If candidates are declining phone interviews, for example, you need to know that. Everyone on your hiring team should update each candidate’s status in the ATS in real time.
Furthermore, you need all the data for accurate analytics. Research shows that 70% of all job listings result in a hire, which means nearly a third of all jobs go unfilled. To understand why that 30% don’t result in a hire, you need data on them. A better approach for the long term, therefore, is to incentivize clean data as well.
5. Train recruiters on basic data management and your ATS inner workings
Data management systems like your ATS aren’t intuitive and can’t make leaps of logic that humans can. They also have their own quirks and even hidden fields.
Free text fields can get pretty unruly without consistent naming conventions. While your recruiters understand that ‘LinkedIn’ and ‘LI’ are the same source, your ATS doesn’t.
Instead of all candidates sourced from LinkedIn going into the same bucket, your ATS will split candidates into separate ‘LinkedIn’ and ‘LI’ buckets. Then someone has to go in and manually combine the two buckets.
If you have someone on your team who’s an expert in your ATS, have them train your recruiters on basic data management and how your company is using your ATS specifically. Make sure they cover any ATS usability issues you may have (e.g., ATS doesn’t do ‘bulk rejects’). A little training can go a long way towards cleaning the data in your ATS.
Clear recruiting analytics are vital
Clear recruiting analytics show trends that affect every hire, but only if the data going into the analysis is clean and represents the full pipeline.
Make sure you avoid using evergreen jobs, tie every candidate to a specific job, track all data including dropouts, and incentivize clean data. If you do, you’ll get clear, actionable recruiting analytics.